Most of us will know ASR from interactions with Siri, Cortana, Alexa, Bixby, Google Assistant or even IBM Watson.
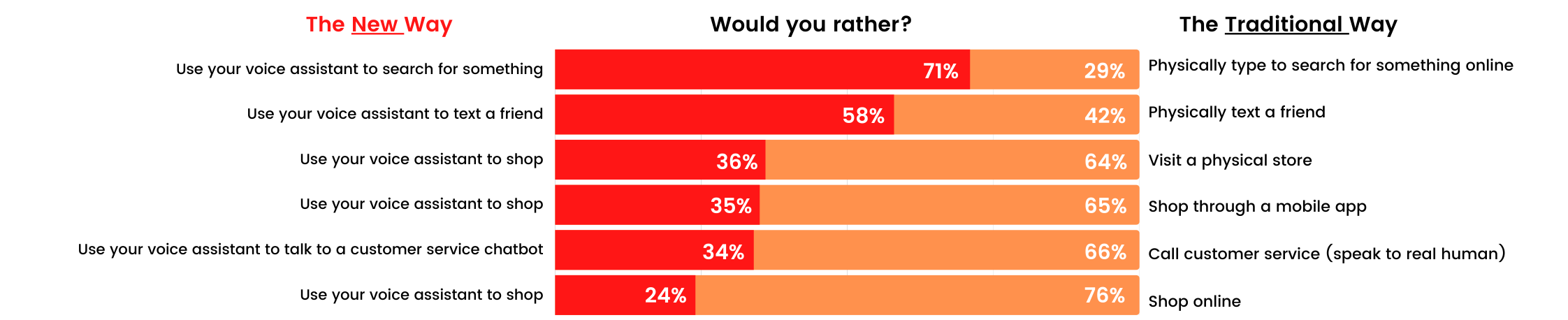
What do we use Voice AI for, really? PwC shows us below:
PwC – How Voice Assistants Stack Up
Voice technology started with a rather ordinary task – transcribing voice into digital signals. Having achieved this over 40 years ago, voice needed the mobile phone to really take off and in 2011, Apple had a hit with Siri – the race was on. Speak some words and it gets transcribed into words on a screen. It took only a few more steps to link the words to some action. How does it work in practice though?
One way we may be familiar with is the appointment. If a customer texts (or speaks) “Book an Appointment”, the AI is should parse the inbound message (“I’d like to book an appointment, please”) to determine the customer’s intent: “Schedule Appointment”. A good model that is trained and optimized can give you about 80-90% accuracy. After Intent Discovery step, the AI will need to discover the date and time for the appointment through a series of questions: “What time would you like to schedule your appointment?”, etc. In Voice AI, this is called “slot filling”. Notice that the AI is looking for a specific answer, a specific word for time, in this example, to fill the “slot”
Accuracy vs. Speed
However, the problems with voice are real. Different accents and background noise reduce accuracy, unusual words may trip up the technology. For example, the National Centre of Biotechnical Information in the U.S. found that transcription word error rates of 25-34% were often encountered. One in three words was incorrectly transcribed!
ASR Performance
Why Voice?
So how does Delvify work with customers to incorporate this technology to deliver better experiences without the high error rates? Firstly, we know that eCommerce sites are primarily arranged around a visual offering. You scroll and point at the objects you are interested. Delvify’s Visual AI technology can harness the amazing sense of sight to help customers search and discover more intuitively and accurately what they want. But for a super-charged experience, our cutting-edge SMART Speech models boost that Visual AI experience.
Dr. Laura Otis writes in Psychology Today that the eyes and ears lie close together on the face and both deliver vital sensory information. Once processed by human brains, however, visual and auditory information offer different, complementary ways of knowing the world and they form varying emotional associations. We may describe an object we have an emotional connection with, but it is only when we see it that we know. Visual acuity is more than 6x as fast as auditory knowledge. We don’t believe a system needs to be perfect if it makes life better for users. If we think of audio as an enhancement to the customer journey and not a stand-alone element, we can imagine a few exciting ideas for your eCommerce experience. We would love to hear more from our readers on their experiences.
Welcome to our store
As PWC notes, somewhere around 80% of respondents think that voice is a faster way to search. So, it is reasonable to state that the demand for voice is real. Indeed, as noted above, speaking our thoughts is often a first step to understanding them. Does your store have a microphone and voice search enabled? If not, you might consider adding this feature to your site as many users will already have their microphone on and waiting. Customers enjoy choice and the integration of new technologies help give power to your customers.
Voice AI is so satisfying because it removes some of the tedious typing. Why not harness this to be the perfect “entrance” to your site? Without so much as a keystroke, your clients can enter your shop say, “I want” and be given a delightful visual array to begin their experience. With the Delvify SMART Speech tool, your customers can speak what you want, and we can show them instantly a collection of pictures for their browsing. Why does this combination work? Our auditory cortex is very good at emoting what we want, but we need the more rational visual sense to get us to where we want to go. Delvify harnesses the natural synthesis of acoustic and visual for your customers to help their journey.
Remind me later
The most popular use of ASR is to transcribe notes or to make an appointment. These are relatively well practiced tasks for voice technology. By creating a small microphone in your Visual AI powered product pages, customers logged in to your site can register their interest by asking to “save this for later” or “put this on hold”, extending the connection to offline rack browsing to online assisted browsing. Just like how you would in a real store, you can take clothes off the rack and have your shop assistant hold on the clothes you want for later. No need to type! The key to the voice assistant is to enhance the Visual journey by synthesizing audio and visual journeys.
Want to pick up in store or try in on later? Using a quick appointment tool to register your intent can become a powerful incentive to complete purchases and foster a more natural connection with your store. This is visual connected to audio.
Dr. Otis’ research revealed that while vision often represents reason-based paths to truth, hearing can offer intuitive paths. Your intuition can get you into the store and your vision can lead you to what you want. Why not let your customers shop with all their senses?
Bonus: Quick Dip Into The Technology
So how do these products work?
The first component of automatic speech recognition is, of course, speech. Speech must be converted from physical sound to an electrical signal with a microphone, and then to digital data with an analog-to-digital converter. It sounds complicated but this is only the easy part!
IBM at INTERSPEECH 2019 sum up the next steps in Voice AI succinctly: traditional "hybrid" ASR systems are comprised of an acoustic model, language model, and pronunciation model. Each component requires complex training. This is different from the current research into Ensemble systems that we will leave aside for now.
What are these models? The acoustic model is a multi-stage process of model training and time alignment. Using a Hidden Markov Model (HMM) the model chops the speech into short snippets of about ten milliseconds. Because we assume each snippet is "stationary" (nothing really changes over the 10 milli-seconds), we can essentially create and plot the "power" of each snippet as some function of frequency. In other words, we can describe the qualities or attributes of that snippet in a group or vector of numbers. The number of attributes in each vector is usually small - sometimes as low as 10, although more accurate systems may have 32 or more. The final output of the HMM is a sequence of these vectors, just a long table of numbers describing each snippet and models that match these snippets to one or more phonemes, the fundamental unit of speech. This calculation requires training, since the sound of a phoneme varies from speaker to speaker, and even varies from one utterance to another by the same speaker. The model uses a special algorithm that can guess the most likely word(s) that produce the given sequence of phonemes. These groups of words are then processed by a Language Model that guess the next word(s) in a sequence, tries to guess intent, sentiment or other Natural Language Processing tasks. Delvify is adept at using the newest BERT models.
As you can imagine this whole process requires much specialized work. In most modern speech recognition systems, there are many shortcuts using neural networks to simplify the speech signal before the HMM recognition. Voice activity detectors (VADs) are also used to reduce an audio signal to only the portions that are likely to contain speech. This prevents the recognizer from wasting time analyzing unnecessary parts of the signal such as background noise. This is not the same as noise cancellation headphones!
Want to keep updated on the latest happenings in AI and Programmatic? Subscribe to our updates and stay in the loop
Our advanced AI solutions help forward-thinking people like you increase online sales, deliver your products on-trend, on-time and on-cost, and deliver digital advertising with precision targeting that scales.
We and our partners store and/or access information on a device, such as unique IDs in cookies to process personal data. You may accept or manage your choices by clicking below or at any time in the privacy policy page. These choices will be signalled to our partners and will not affect browsing data. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience. To see what cookies we use please visit our Privacy page here.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.