

One source of continued focus over the past year has been on Linear Bandits (no, this is not a Money Heist sequel), the core problem of sequential decision making. This is somewhat analogously to some problems with linear programming in optimization or linear regression in statistics. Despite its importance, we still do not have a complete picture for this problem. In some cases, we have optimal strategies (from an information theoretic point of view) but they are algorithmically intractable, while in other cases we even lack information optimal strategies. Very simply, a Linear Bandit system tries to minimize the loss over all time steps. This is critical to packet routing (routing data along the optimal network), but we can give two more intuitive examples.
Imagine you want to bike to work each day and you want to take the fastest route. Each day there will be some delays due to road works, or accidents. You might have full information (know where the delays will be on all streets), semi-bandit information (you can collect and record the delays on the paths you choose and have an idea of the delays on your chosen route) or have very limited information (just the time you have driven along each route you have taken in the past).

The Linear Bandit model finds the optimal route for you with whatever information you hold. It does this by playing a kind of game to find the best route with the worst conditions. Another example might be a bookstore owner. If someone visits your shop and you want to recommend a book and your reward is the revenue earned, you might construct a map of all the topics of the books, the interests of all visitors, etc. If you want to run a simulation to find the optimal books, a Linear Bandit system may be good because it can help you to find the best books given the journey a customer takes.

Expect more of this super accurate method to help with routing of deliveries and recommendations!
Another place of interest are data sets with latent factors or latent variables. This is a source of interest at Stanford. Latent factors are not the factors that somehow cannot get their act together and always show up late, rather they are the factors or variables that are not directly observed (i.e variables that are directly measured). For example, I might know you like coffee because of the Starbucks mug on your desk. I never observed you drinking coffee, but I can guess you like coffee.

This problem is very interesting to solve because you can improve understanding. By extracting the latent factors in data capture and using them to generate semantical variations is crucial to creating better, more interesting labelling and better human understanding. How might this work? If I can separate the shared factors between two images, for example, I can better predict their correlation (“these are both cats because they both have cat ears and tails” for example) and use the private factors to guess domain specificity (“this is a Tabby because of the forehead mark, that is a Persian due to the short muzzle”).

What else might this mean in practice? Well, most state-of-the-art image captioning models adopt an encoder-decoder architecture which encodes the image into a feature representation via Convolutional Neural Network (CNN) and then decodes the feature into a caption via Recurrent Neural Networks with Long-Short Term Memory units (LSTM). It is utterly amazing, but the problem is that the captions generated all become very synonymous and syntactically similar. “A cat” and “a person”, is far less descriptive than, something like, “a cat is sitting next to a person begging for attention”.
Expect many more diverse labels of images, your products for example or a description of what an influencer is doing in a picture.
One debate in AI is the difference between clever and brute force. Is it better to just grab every single bit of data and make a huge machine, or is it better to create a clever machine? Our brains are clearly small and clever. OpenAI burst into view this year with the reveal of GPT3. A massive advance, it chose brute force by building an enormous model of billions (175B) of parameters and scraping the entire web.
Back on Earth, if we look at the history of NLP we can see that we have gradually increased the size of context we can analyze.
Word: word2vec (2013)
Sentence: ELMo (2018)
Paragraph: BERT (2018)
Corpus: GPT3 (2020), T-NLG (2020) etc.
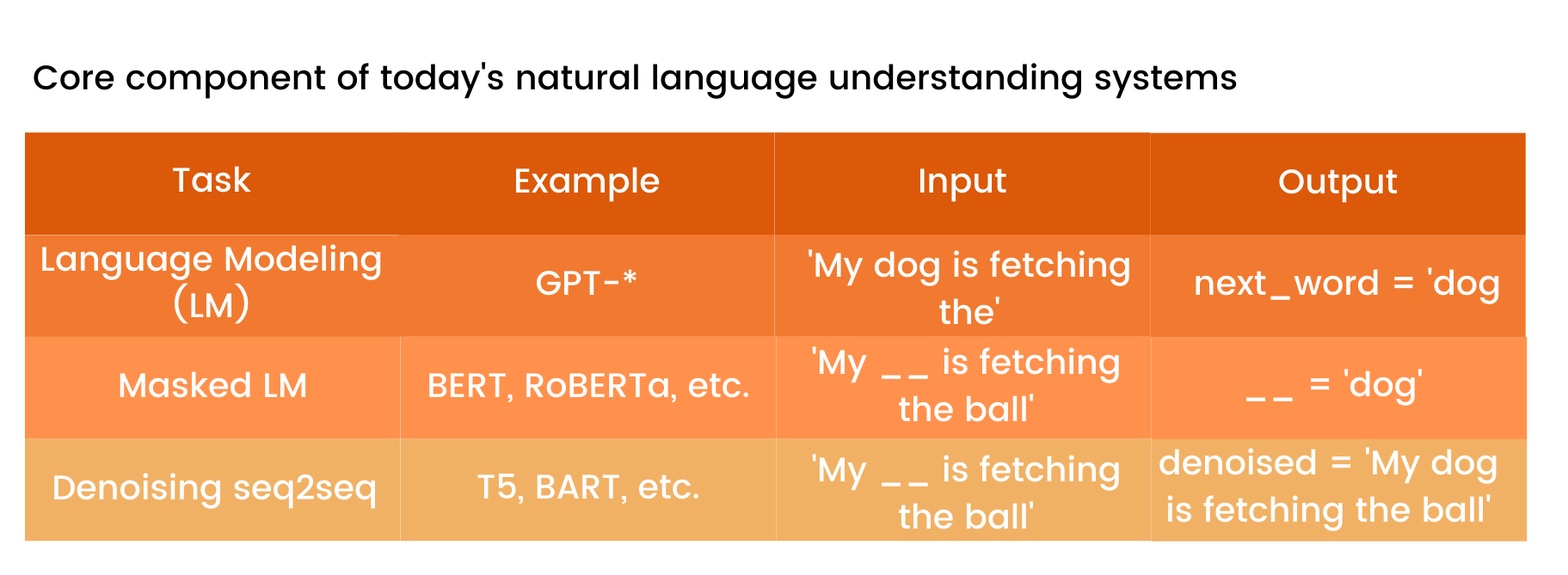
As we get ever larger and the model gets bigger, we may remember more but implicitly harder to understand what knowledge it is using. In addition, the complexity does not lead to speed. Many new ideas are focusing on reducing latency and creating simpler, more tractable-like models.
Ensemble strategies are the committees of AI models. Until present, we have seen single learning algorithms of growing complexity. Ensemble Strategies are a (relatively) new method designed to improve better predictive accuracy by combining or chaining the results from different models based on different data samples and algorithm settings. Ensemble strategies divide themselves into two main branches. The first is known by names such as, Simple Voting, Bagging, Stacking, and Boosting, the ideas is that we get a better result by either using one model to learn how to combine the components of another model.
The second method is to use the average of a few different models. This gets us closer to mimicking human behavior as humans modify their behavior based on new information but rarely change it completely. Fatai Anifowose of EXPEC Advanced Research Center, Saudi Aramco explains it like this:
- We ask for a “second opinion” from several doctors before undergoing a medical or surgical procedure
- We visit several showrooms or read reviews of different brands before buying a new vehicle
- Journal editors seek the opinions of reviewers before deciding whether to accept a manuscript. (In fact, several reviewers read this article and their suggestions were implemented to evolve the final version.)
At Delvify, we constantly improve our models and processes through relentless research and discovery. By incorporating different strategies and models into our recommendation tools we implement a form of ensemble strategies. This helps to align the Visual results with the product a user is searching for – we don’t rely on only a single factor to determine relevancy. Delvify also believes in using as advanced a model as possible. We were one of the first to incorporate BERT transformers into commercial products and will continue to upgrade and improve our features into 2021.
We believe a few reasons will cause an explosion in true AI applications growth in the coming year. Namely: Architecture, GPUs and better mathematical models.
Architecture: inception modules, attention networks, adversarial networks and DeepRL have all created new applications from deep fake videos to better natural language understanding.
GPUS: The advances by Nvidia and other combined with the open-source power of Tensor Flow allow quick and speedy optimization viable over hundreds of millions of observations such as is needed in Visual AI.
Standard Gradient Descent: With better standard gradient descent methods for nonconvex loss functions, we can now find the local minima close enough to the global minima to make quick and accurate assessment of complicated data sets.
These three hint at a real world of possibilities for better eCommerce, healthcare and supply chain management.
2021 will be a time for the AI landscape to flourish and mature extensively to create a permanent footprint within the history of eCommerce. Let’s put all the negativity from 2020 behind us and look forward to creating a better 2021! This is the last eCommerce AI blog of 2020, so our team would like to wish you Happy Holidays and a Happy New Year. Stay safe!

Get in touch with our team today to change your customer experience with Visual Search before the new year starts!

